
Tip of the Week: Make Fine-Tuning LLMs Boring (In the Best Way Possible)
I spend a lot of time fine-tuning large language models (LLMs) to, ironically, help builders and researchers lessen the tedium of MLOps tasks like dataset preparation, infrastructure setup, and model validation.

If You Think We Love Dogs - We Do
I’d like to share some of my experiences in a short demo video (Robbie Tune) that compares using Robbie vs. AWS for one particularly acute problem of training compute infrastructure.
I provide some examples using popular training frameworks PyTorch torchtune and Oumi, and I have also successfully used Robbie with Huggingface transformers and Ray.
Our primary motivation is to enable fine-tuning using these frameworks without writing (much) code – thus making fine-tuning more accessible to anyone without advanced Python or cloud skills.
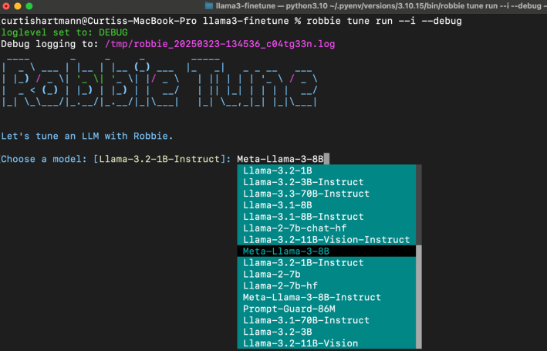
Suppose you like the efficiency of a command line (and took high school typing like me). In that case, we have a simple way to kick off fine-tuning jobs from a local shell – just select your data, a model, a recipe, and the evaluation criteria. Robbie handles the heavy lifting: finding the proper hardware, installing dependencies, training, and evaluation: no tedious cloud setup and software installation.
We’ve also streamlined the process of moving from experimentation to full-scale fine-tuning. Many people like experimenting with Jupyter notebooks before investing the time and resources in full-scaling fine-tuning (or further pre-training). The challenge comes when you’d like to scale up for full-scale training on a cluster, which typically requires refactoring your code and then trial and error to get it running. With Robbie, you can run your existing notebook (with no code refactoring) as a cluster job by simply adding two lines of code to the first cell of your notebook: import robbie robbie.init().

When you execute the first cell, Robbie pops up a small GUI in the notebook, enabling you to “launch” the notebook as a computing job. All data (configurations, datasets) associated with the job are copied to and stored on the lo
Enjoy!

